
我好像還頗愛講華為的,上次的天通衛星事件也是,這次來講講「τ 定律」 。
最近華為何庭波發表的「τ 定律」被產業媒體炒了一陣。這東西真正的動作不在技術細節,而在重新定義整個產業的 benchmark,而實際要加速的是降低通訊的 latency。
可以非常簡化地壓成兩句話:
- 將晶片進步的單位從 nm 換成時間 (τ)
- 想盡一切辦法,在固定工藝下縮減 end-to-end 的 τ
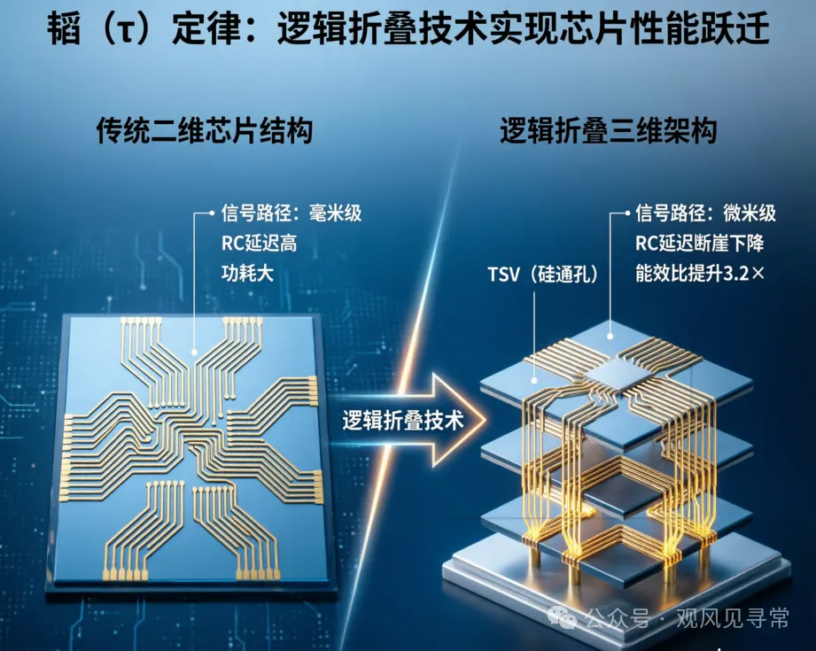
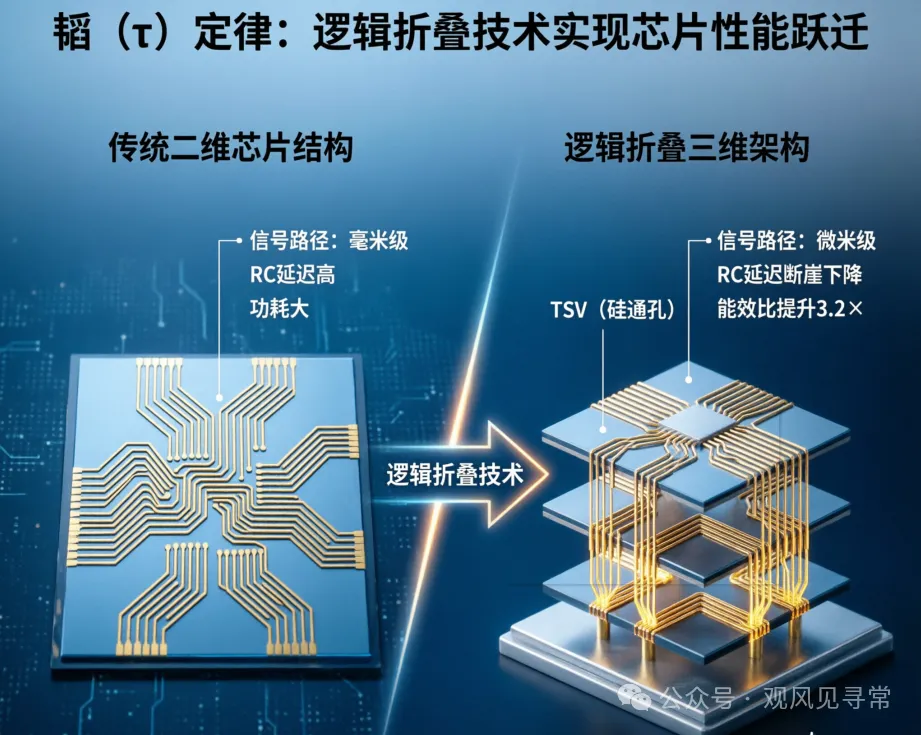
其他什麼 LogicFolding、Unified Bus、Hi-ONE 近封裝光 I/O、3D Folding,都是在服務這兩件事。
第一點:為什麼 nm 這個標準已經不準了
過去衡量晶片進步用 nm 當主指標,但今天的 nm 早就只是等效命名。3nm、2nm 跟二十年前的 90nm、65nm 不是同一種意義上的「尺寸」——製程的實際參數、密度、效能,跟那個數字早就脫鉤,真正的工藝水準要看製造端的具體參數。
所以大家早就知道,用 nm 當製程指標,本身就已經失真。只是因為要讓一般人看懂,所以用降低 nm 數字還是比較簡單,但是 nm 背後的各種製程也有可能降低功率增加效率等等,因為複雜度變高,比較少人提。華為就是因為進步不了,所以直接訂一個新指標,也就可以重新定義「進步」是什麼。τ 就是這把新指標——從電晶體狀態切換、電路傳遞、搬移資料、響應時間等等,全部換算成同一個時間單位。算出 τ,比較 τ,就知道效能進步了多少。
也就是說:華為要用這個方式搶未來的話語權。當主流指標已有失真問題,華為被卡在技術上怎麼追都是輸——那不如重訂規則,重新制定話語權。
指標失真這個現象其實之前極客灣的手機評測就點出過。手機廠針對 benchmark 軟體調校效能,表面上像在作弊。但更深層的問題是:如果手機廠不調校,各代 CPU 的差異看起來不會這麼大。背後的真相是,製程縮小對特定應用早已沒有當年那種代際差距。這就是 nm 指標失真的實證——當指標衡量不出真實進步幅度,要嘛靠調校放大差異,要嘛換一種指標。
第二點:為什麼是 latency ?
縮小製程的好處之一,本來就是降低元件之間的 latency——線變短、RC 變小、訊號跑得快。但反過來想,如果在舊製程上也找得到降低 latency 的辦法,效益是等價的。
LogicFolding 把原本在平面 layout 上隔得遠的邏輯閘折成上下兩層,靠 hybrid bonding 用「垂直電梯」代替較長的訊號傳輸線——本質是壓 RC 延遲。Unified Bus 把跨節點存取從幾十微秒打到百奈秒級,本質是把網路堆疊裡 packet 打包/解包/協定轉換的 latency 砍掉。Hi-ONE 把光收發器貼到晶片家門口,本質是用光速代替電在銅線上跑。
不同維度,同一個動作:在固定工藝下,把整條路上每一段 latency 都當成可以攻擊的對象。
還有在傳輸協定上降低延遲——選擇性放鬆某些環節的 error check,把省下來的功耗抵消製程無法進步跟對手的功耗差異,另外因為很多層不用檢查,還可以同時降低 latency 和減少 latency 浮動的手段。傳統做法是 PHY 層把 BER 壓到極低、FEC/DSP 把每一 hop 做乾淨,代價是 PHY 燒一堆電、佔一堆 die area。Hi-ONE 反過來:PHY 故意跑寬鬆 BER,錯誤交給上層協定吸收。重傳會慢一點,但對 AI 這種可容忍延遲的 massive block transfer,整體 throughput 應該還會上升;省下來的 PHY 功耗和面積,剛好抵消製程落後的缺陷。
對沒辦法用先進製程的華為,能省一點是一點——這是個典型的 cross-layer 取捨:用協定複雜度換 PHY 功耗。
這其實就是 τ 的真正優勢。不管是 AI 訓練/推理或是傳統 CPU,即使 CPU 有 out-of-order、speculative、prefetch 這些微架構手段在後面默默掩蓋 memory latency,而降低 latency 對這兩個應用都有幫助,尤其是 AI 這種 massive block transfer 應用,沒有 ILP 可以隱藏,直接拉高 utilization,讓 GPU/NPU core utilization 再上一層樓,另一層意義也是可以降低 HBM 跟不上別人的劣勢。
所以為什麼是華為,而不是其它主流產業鏈?
這些技術方向其實都不新——logic-on-logic 堆疊、memory-semantic fabric、linear pluggable optics,西方陣營都在做。但做成整套 stack 的能力是結構性的。
主流產業鏈(台積電—NVIDIA—Synopsys/Cadence—生態軟體)做不到這件事,原因不是技術不夠,而是跨公司要整合這件事要大家都有共識,但是實際上大家都有大家的邊界,靠的是 SPEC 定義這個邊界,不照邊界做事就會出問題。台積電做 SoIC 是賣服務、EDA 屬於 EDA 廠、設計屬於客戶、軟體屬於生態——每一個公司邊界都是跨層最佳化穿不透的牆。
華為從 EDA、製造、封裝、OS 到 AI 框架一條龍。這個結構讓跨層的 τ 最佳化變的容易許多,只要華為有想法,他們就可以做。而經歷過生死存亡的華為最知道什麼時候該放手去突破。
而且制裁反而變成 forcing function。NVIDIA 可以力大磚飛、靠先進節點和大晶片繞過 3D 的難題;華為沒有先進製程,也沒辦法依賴 TSMC 的 CoWoS,也沒有先進的 HBM,所以必須提早把跨層折疊、UB、近封裝光 I/O 這些能降低 latency 的技術提前用上。
而這些壓榨效能的技術,跟 EUV 不是替代關係,是疊加關係。如果哪天中國的 EUV 真的做出來,這些技術不會作廢,反而會疊在新製程之上繼續放大。這代表華為在受限狀況下練出來的這套東西,一旦約束解除,會把這幾年累積的方法學整體向前帶,可能把效能往前推進好幾個世代。
那麼,代價是什麼(At what cost)
垂直整合是要一步到位,任何一層失敗,整個 solution 就會出問題。而模組化分工本來就是資訊業界非常成熟的方式,大家分工明確,效率很好,華為的東西其實也還沒有真的擴散出去——的確有少數廠商採用,但論廣度還太少,目前比較實際的擴散範圍是中國國內。τ 要當定律,還要說服許多有能力沒意願的玩家加入,不過還好有川建國先生和前後任大力支持著,許多不該有意願的都會有意願加入,而未來是多極世界,在可見的未來美國會不會出新招不知道,人人都要買個保險自保,尤其是中國大陸的企業。這個架構,不會是全球的標準,連中國大陸內部多數企業也不一定會用,但是華為的標準就在那邊,未來慢慢的滲透也是有可能的,或許只是還沒到那個爆炸式成長的華為時刻而已。
對華為是戰略上重要,但並不會是「全產業範式轉移」
西方在用拳擊看中國,中國用太極回應世界。力大磚飛很好,但被制裁打不了那套的時候,借力使力一樣可以下殺手。EUV 拿不到,就不在幾何維度對打,改在拓樸、互連、系統維度落子。
這份文件不是摩爾定律的繼承,它是一份在受限條件下重新組織戰場、並重新訂規則的獨立宣言。它值不值得被當成教料書的指標?要看未來華為能不能將整條路打通,是不是能拿出夠驚豔的產品。但是華為突破封鎖做出5nm 晶片,本身就是一個值得讓這篇文章出現的事件,從技術角度來看,我也很希望華為成功,畢竟這個思路也是很令人興奮的。

發佈留言